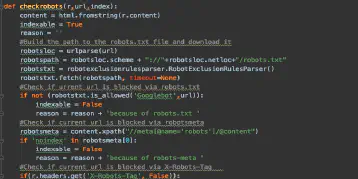
SEO QA & Monitoring mit Python – Teil 2 – Indexation Status
April 18, 2020Nichts ist schlimmer im SEO Bereich als Seiten die auf einmal aus dem Index verschwinden oder gar nicht erst aufgenommen werden.
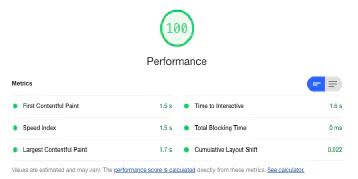
Google PageSpeed Insights API mit Python abfragen
October 4, 2019Überprüft mit Hilfe der PageSpeed Insighs API die wichtigsten Metriken eurer Seite
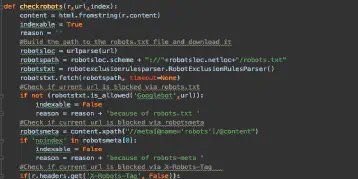
SEO QA & Monitoring mit Python – Teil 1 – Status Codes
September 27, 2019Mit Hilfe von Python schnell und einfch den Status-Code beliebiger URLs checken